Design Decisions & Implementation Challenges
The Database — SQL vs. NoSQL
To deliver automatic real-time updates across all connected clients, we chose MongoDB because documents naturally map to application objects. Consider a project management application built with Pendulum: when a user updates a project task, we can instantly push the full updated task to all connected clients without any backend queries or joins, since MongoDB's document model keeps all the related information together in one place.
This document-based approach also perfectly supports our target users — solo developers and small teams prototyping collaborative applications. Developers avoid database migrations as their data model evolves, and new fields can be added without breaking existing data.
Mongo’s flexible schema suited our needs, but it was not without downsides. While possible, Mongo lacks the ability to efficiently join data across collections for complex querying, aggregation, and reporting. Additionally, Mongo pushes much of the data access responsibility to the application level, which creates additional complexity within the application server.
Alternatively, we considered using a traditional SQL Database — a decision many BaaS providers opt for. SQL's complex analytical querying ability is great for applications with highly relational data or those requiring extensive reporting. Furthermore, many SQL databases have built-in row-level access controls which make securing backend data more straightforward. However, SQL’s rigid schema requirements did not align with our need for a flexible data model.
| SQL Database | NoSQL Database |
|---|---|
| Rigid schema, requires migrations when schema changes | Flexible schema, no migrations needed |
Complex JOINs needed for real-time broadcasting | Complete documents broadcast instantly |
Excellent JOIN support, complex analytical queries | Limited cross-collection JOINs, simple aggregations |
| Row-level security, fine-grained permissions | Application-level security implementation |
Data Validation
Frontend developers shouldn't have to worry about complex data validation when prototyping applications. While MongoDB's flexible schema enables rapid iteration, malformed data could crash application logic — so we built comprehensive validation that runs automatically without any developer configuration.
Pendulum handles all data integrity through middleware validation that runs before your data reaches the database. Every API request is automatically sanitized, validated, and normalized with custom error codes, so developers can focus on building features while we ensure data consistency. This centralized validation means consistent protection across all endpoints without writing validation code.
With the middleware approach, every request passes through a series of validators, even requests that may not strictly require validation. While this centralized approach increases latency for API calls, the alternative was implementing validation logic directly inside each database controller. Controller-level validation can catch errors closer to where they would cause problems, but result in significant code duplication and increase the risk of missed edge cases as validation requirements change.
Enabling Reactivity
Our real-time design consists of a single method call that makes any
application reactive — client.realtime.subscribe('collection', callback) — but how do we facilitate this level of simplicity? All CRUD operations with
Pendulum are done over standard HTTP. Given this, we recognized that our real-time
data synchronization only needed to flow in one direction. When an update occurs,
the events server pushes updates to connected clients without the need for a
response back.
The uni-directional communication channel of server-sent events was exactly what we needed for our use case. Server-sent events are simple to implement and many web browsers even handle client reconnection by default.
We considered both WebSockets and polling as potential options for our real-time functionality, each with distinct tradeoffs. WebSockets’ bi-directional communication channel works best for applications that need to allow messages from the client. Using a single communication channel for database operations and real-time updates makes for snappier responses, but, like we mentioned earlier, requires the developer to write more backend-related code. WebSockets also add additional complexity in managing connection state in distributed systems as applications scale.
Polling is the simplest to implement but adds strain on the server and is relatively ineffective for true real-time updates.
Backend Design
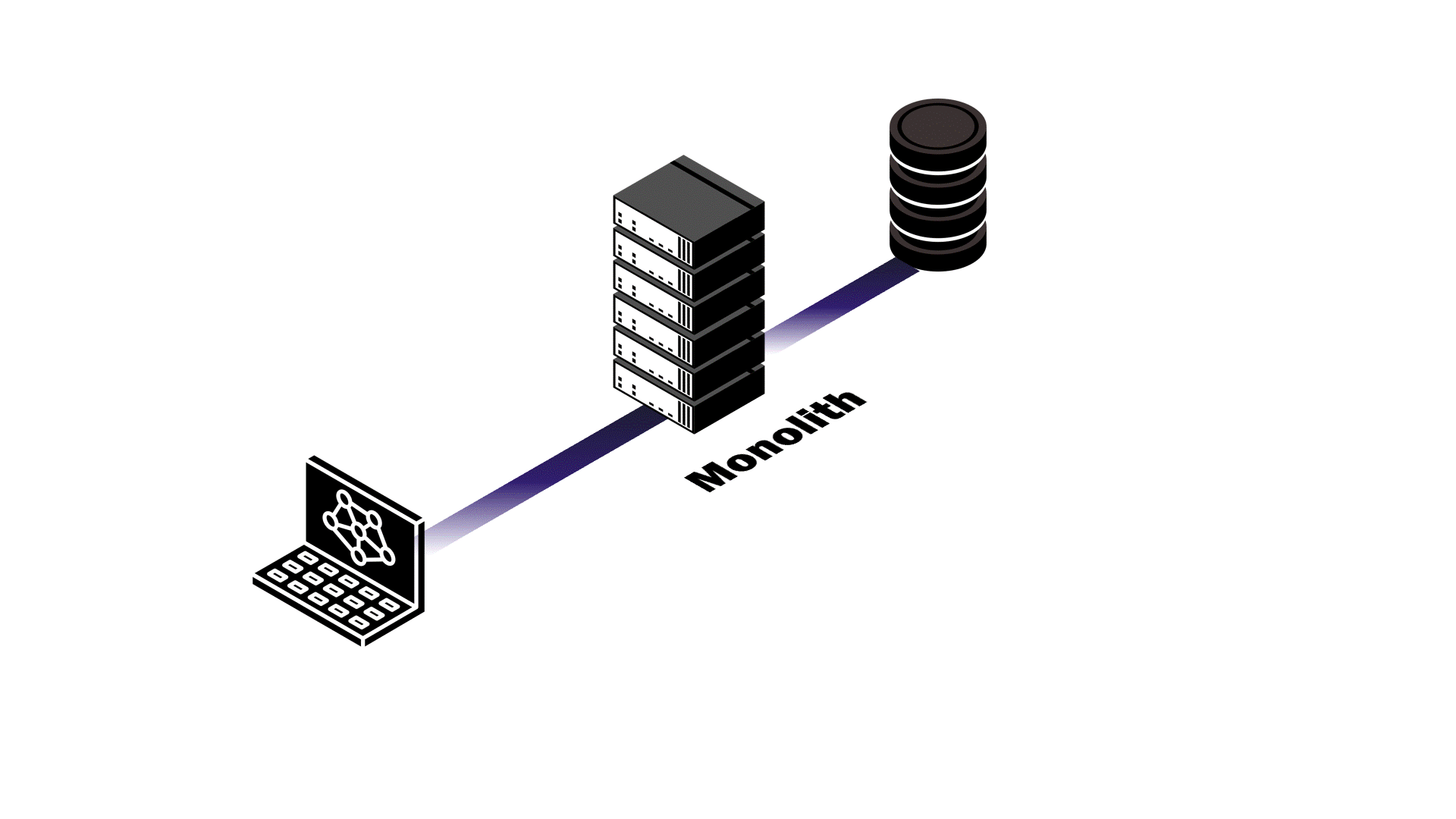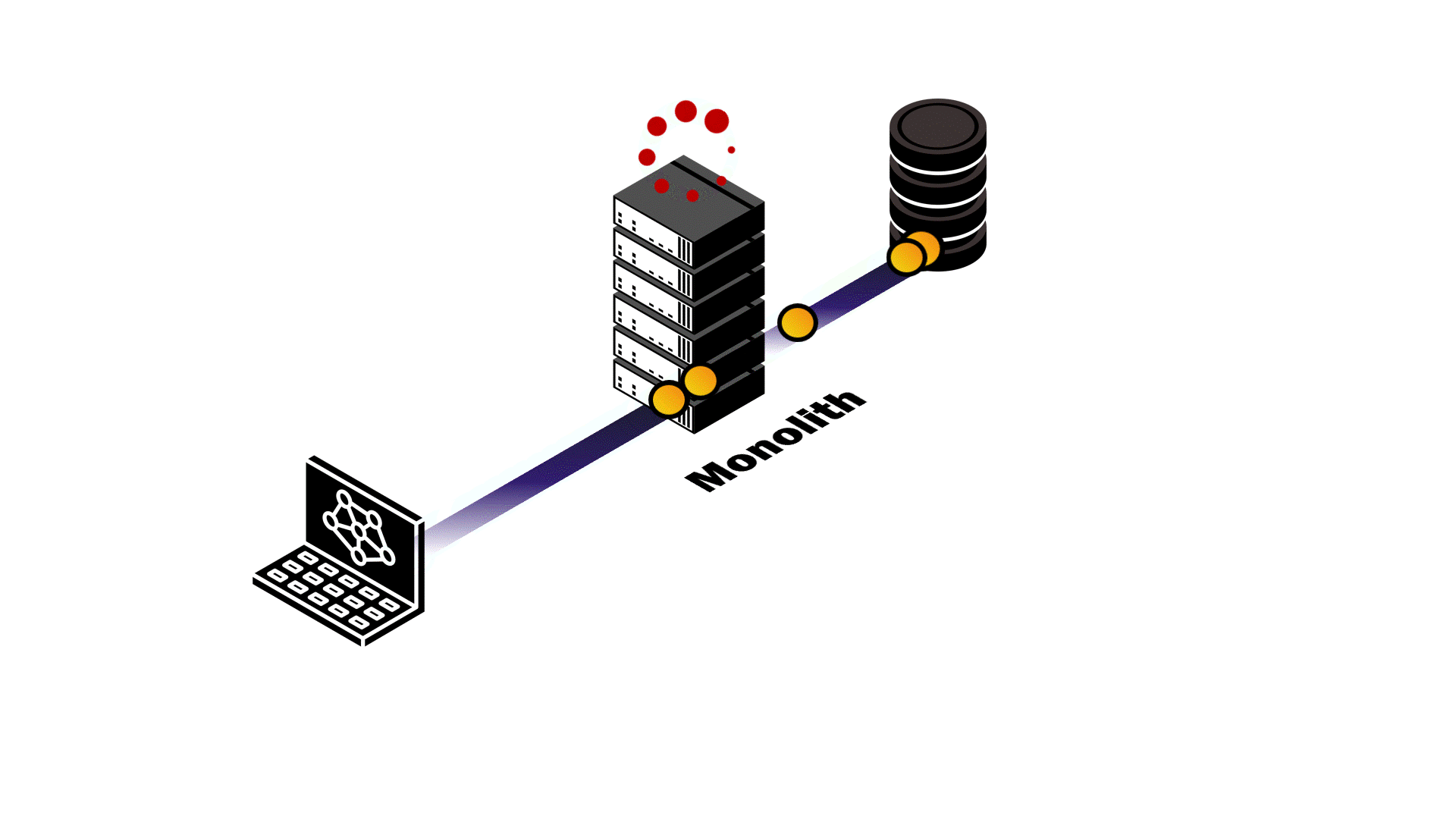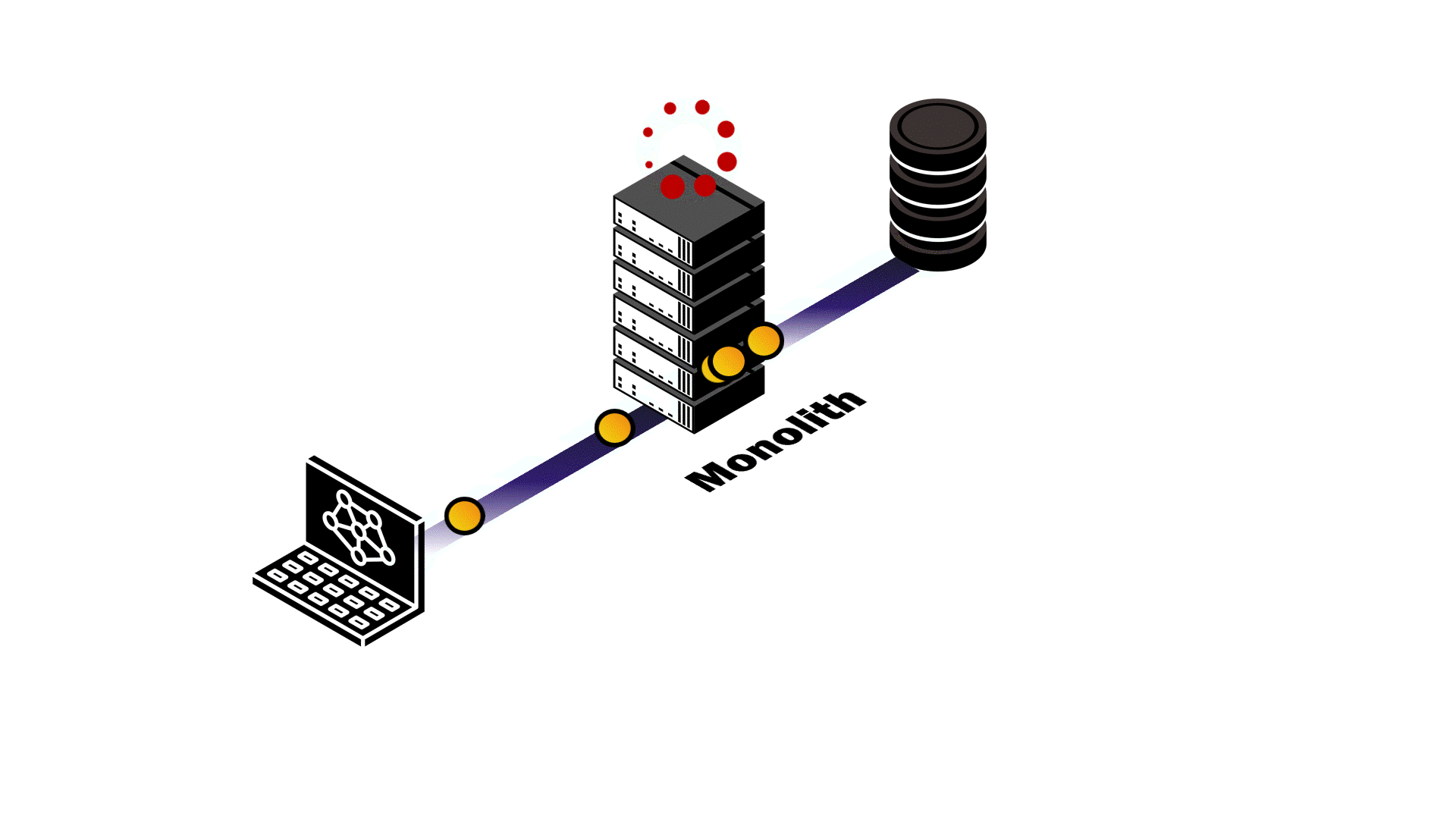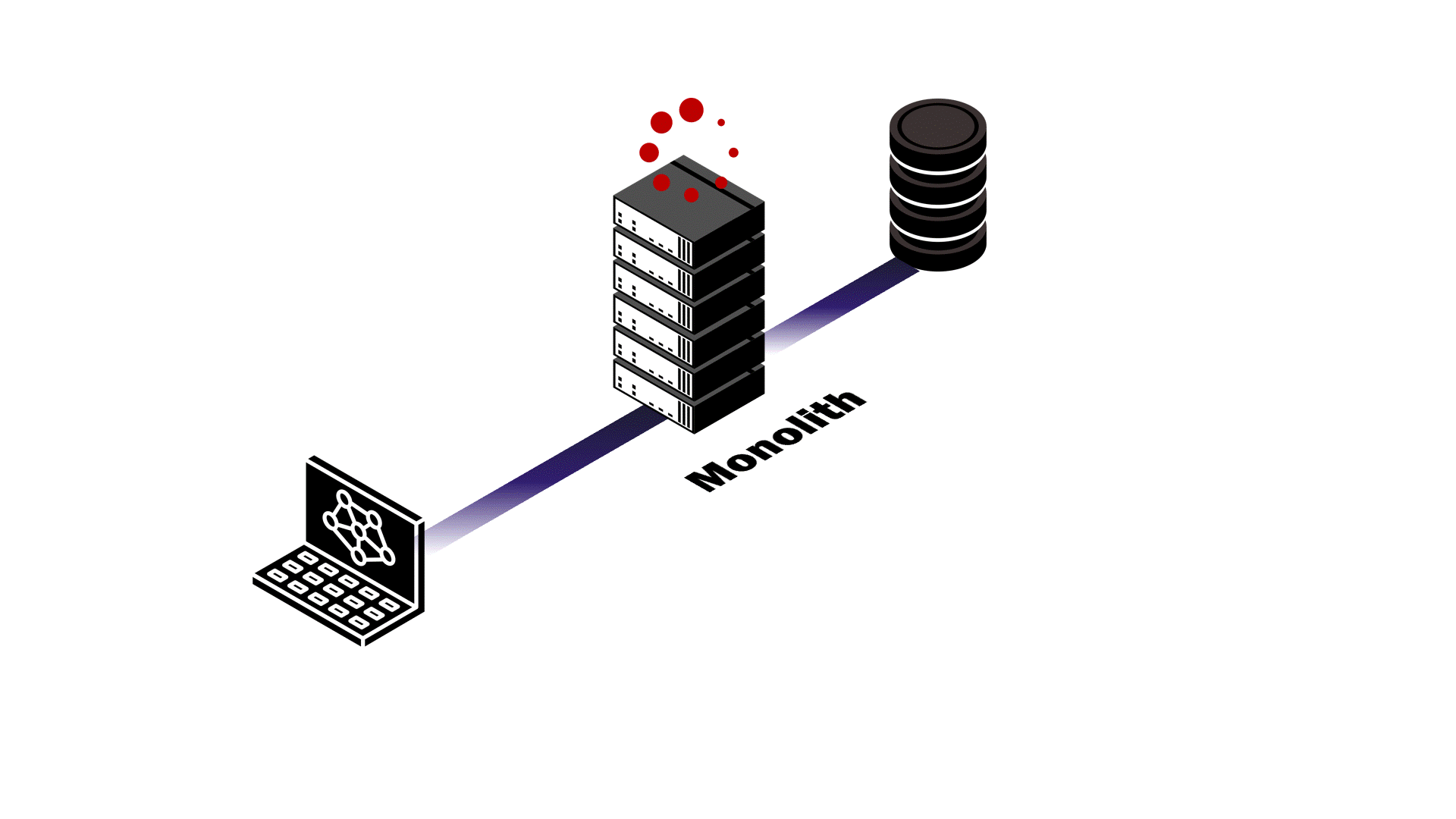
At this point, Pendulum’s backend was a monolith where the application server and events server were a single service. The service handled API requests, data validation, authentication and authorization, and broadcasting database change events in real time. We anticipated difficulty in trying to make this architecture scalable, so we examined different application usage patterns to assess potential outcomes.
Take two reactive applications with similar load that use Pendulum for their backend: one with a high read-to-write ratio, and another with a low read-to-write ratio. In either example, resource contention between the application server and the events server is inevitable.
In the first example, the vast majority of requests are simply querying existing data. As a result, there are relatively few database mutations happening that would require our events server to broadcast events to subscribed clients. Despite the lack of database events, the events server still has to maintain the connections to subscribed clients. This pulls necessary resources away from the application server and slows down API response time. In the second example, the high number of writes to the database that the application server makes uses resources that the events server needs to send updates to clients. The result? Both services are negatively impacted. API response latency increases and real-time updates fail to happen in real time.
By shifting to a microservices architecture, each server is separated out into distinct services with well-defined responsibilities. The app service only requires resources for handling API requests and delegates real-time updating to the events service. The events service’s job is to maintain persistent connections and broadcast database change events.
To implement this de-coupling, we created an in-memory eventClient whose sole responsibility is to bridge the two services. When the app service
completes a database operation, the eventClient makes a single HTTP
POST request to the events service at an internal endpoint with
the details of the change. When the events service receives a database event,
it distributes the message to all actively connected clients. This separation
allows each service to scale independently based on actual usage patterns — a
key feature in enabling a scalable architecture. In the end, loosely coupling
these services means database operations complete quickly regardless of active
users, and real-time updates can be broadcast without bogging down API responses.
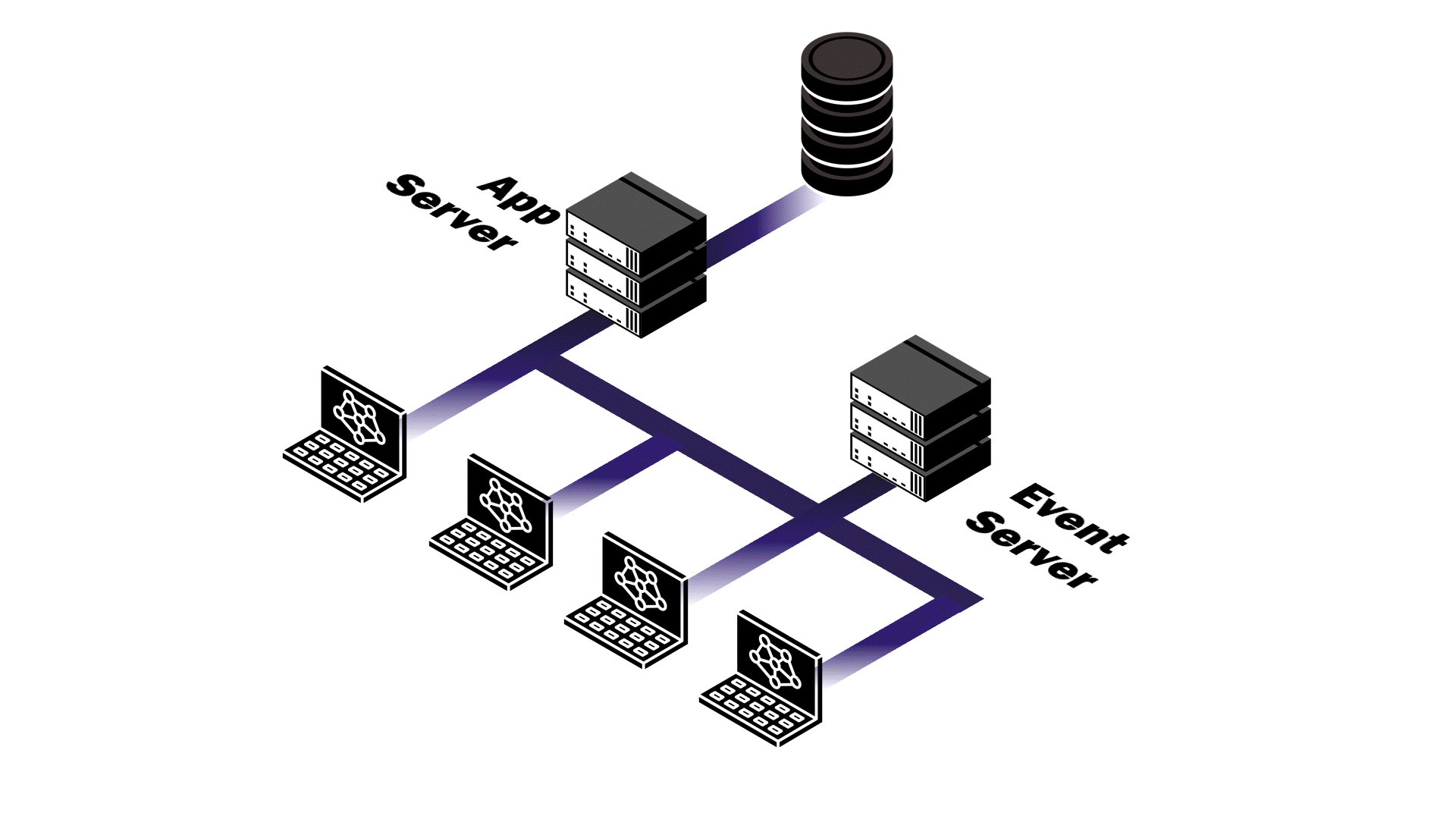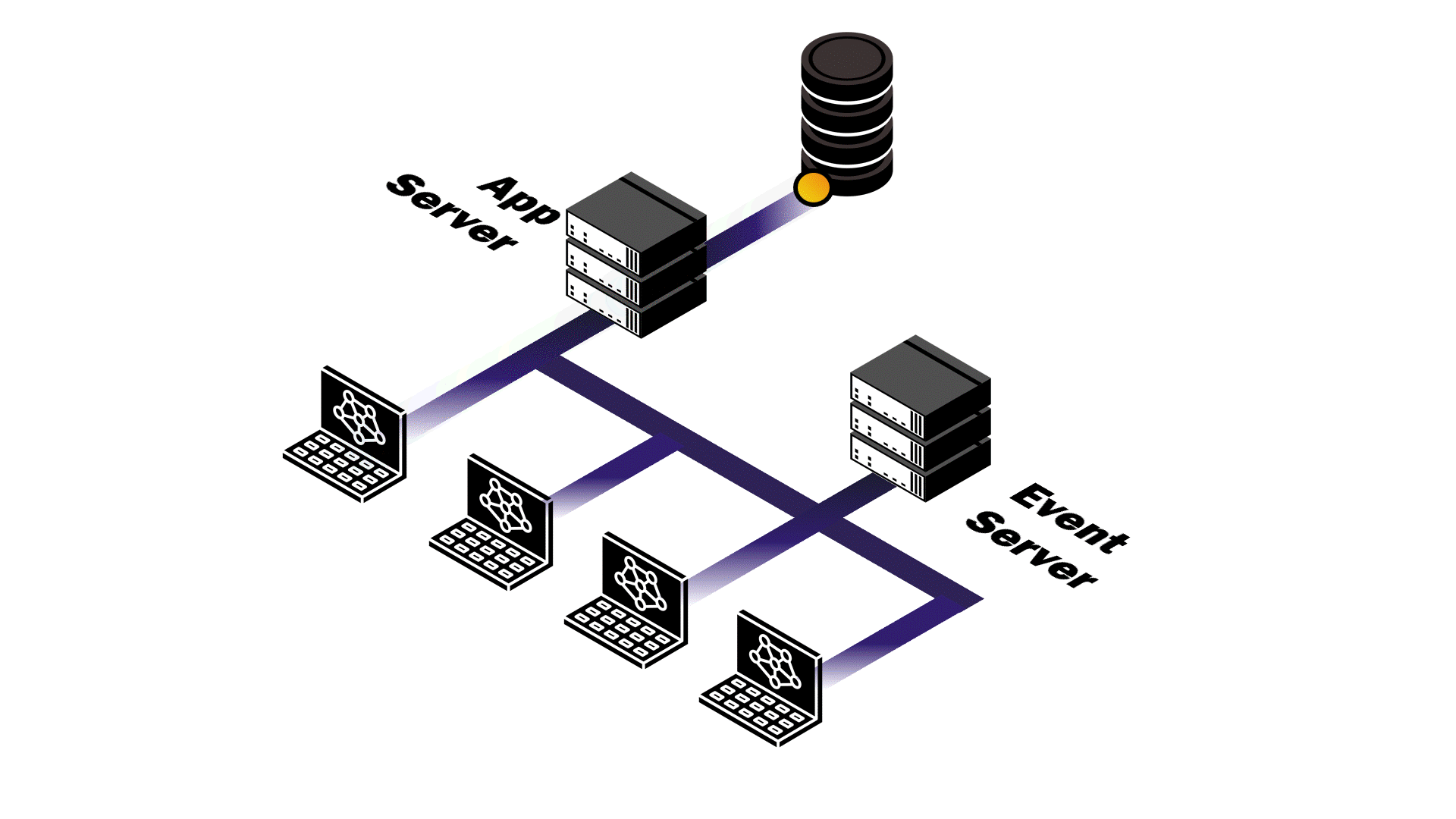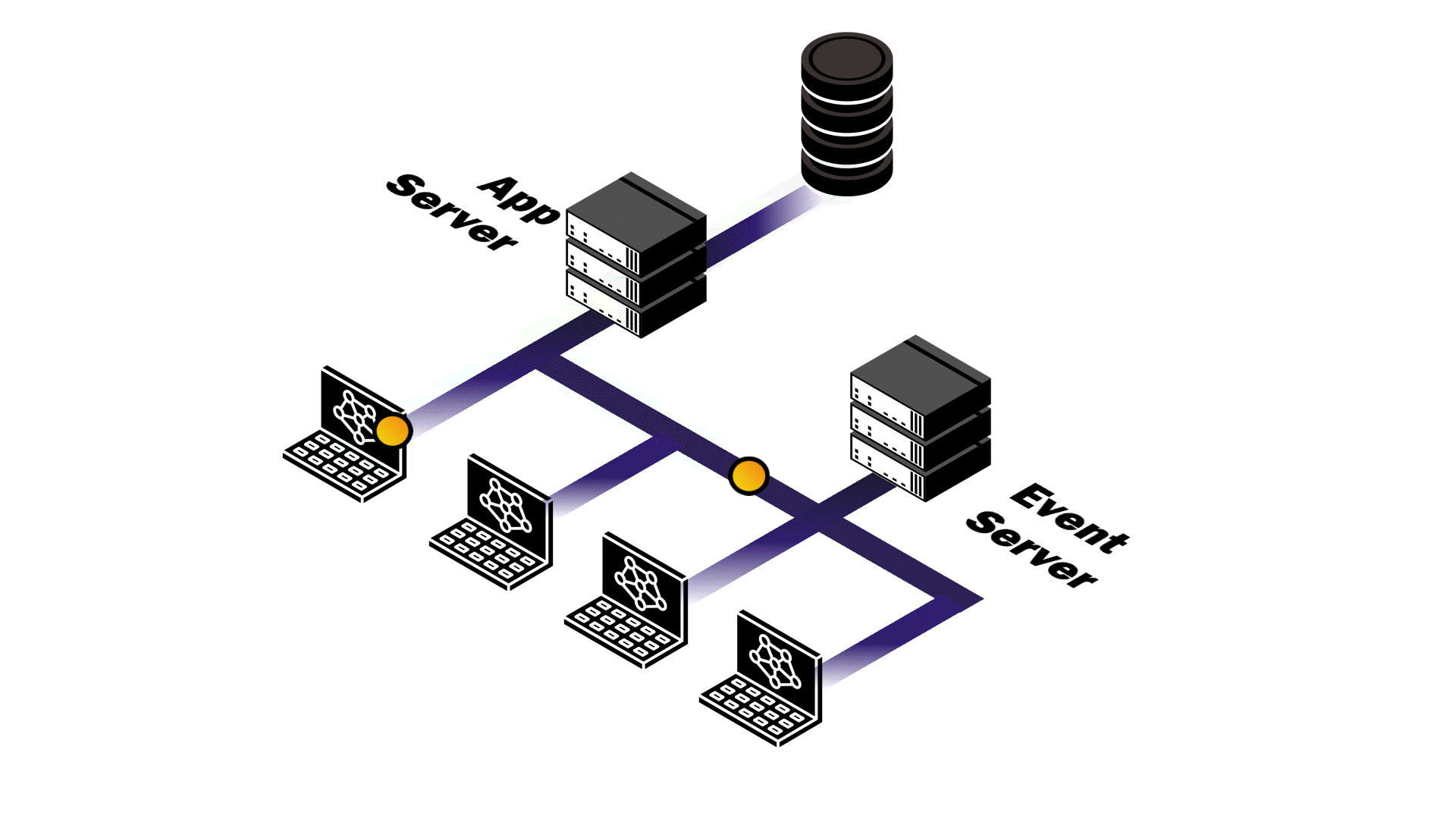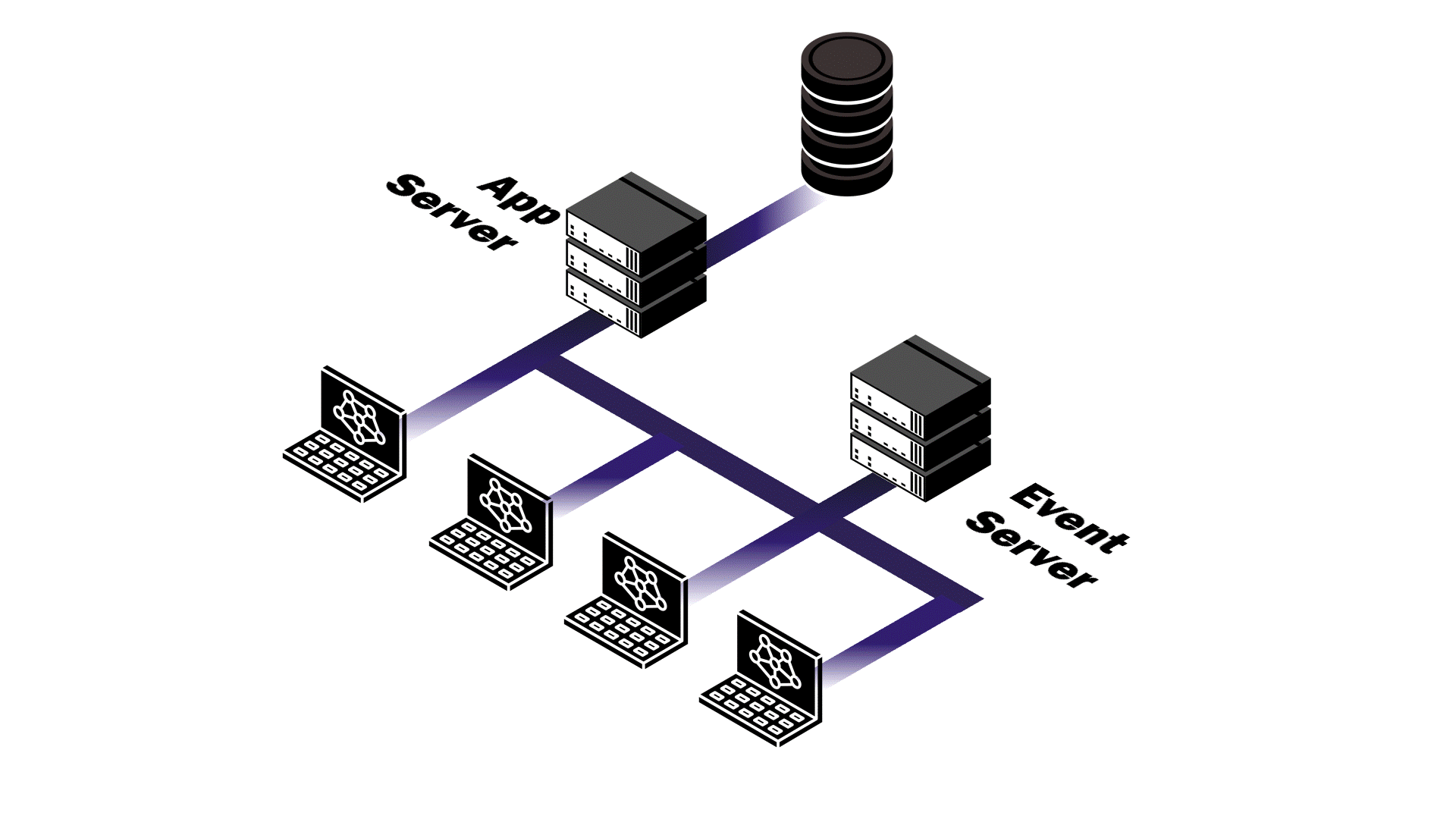
Though it suits our use case, microservices also introduce network latency and interservice communication adds complexity to the implementation. The monolith is simpler to implement, offers easier deployment, reduced network latency, and makes debugging more straightforward. Despite these benefits, a monolithic approach would require the entire application to scale regardless of which component actually needs more resources.
Our approach allows developers to deliver reliable real-time updates without managing any of the architectural complexity.
Handling Reactivity in the Frontend
With our reactive design implemented in the backend, we faced new reactivity-related challenges on the frontend. Frontend developers commonly design applications to immediately reflect database operations in the UI through optimistic updating. In applications with real-time updates, developers also need to incorporate changes in backend state from other users' actions. The combination of real-time event subscriptions, application state, and API calls can lead to synchronization problems between optimistic updates from frontend actions and event-driven updates from the server.
Our main challenge was figuring out how to provide a mechanism to ignore database event notifications generated by the same client. Immediate local updates provide superior user experience by making changes appear instantly in the UI. Conversely, server-first updates ensure consistency but introduce lag to the end user.
For Pendulum, we prioritized the use of immediate local updates to improve
application responsiveness. We implemented a client-side management system
to track outgoing database operations and filter incoming events. When a
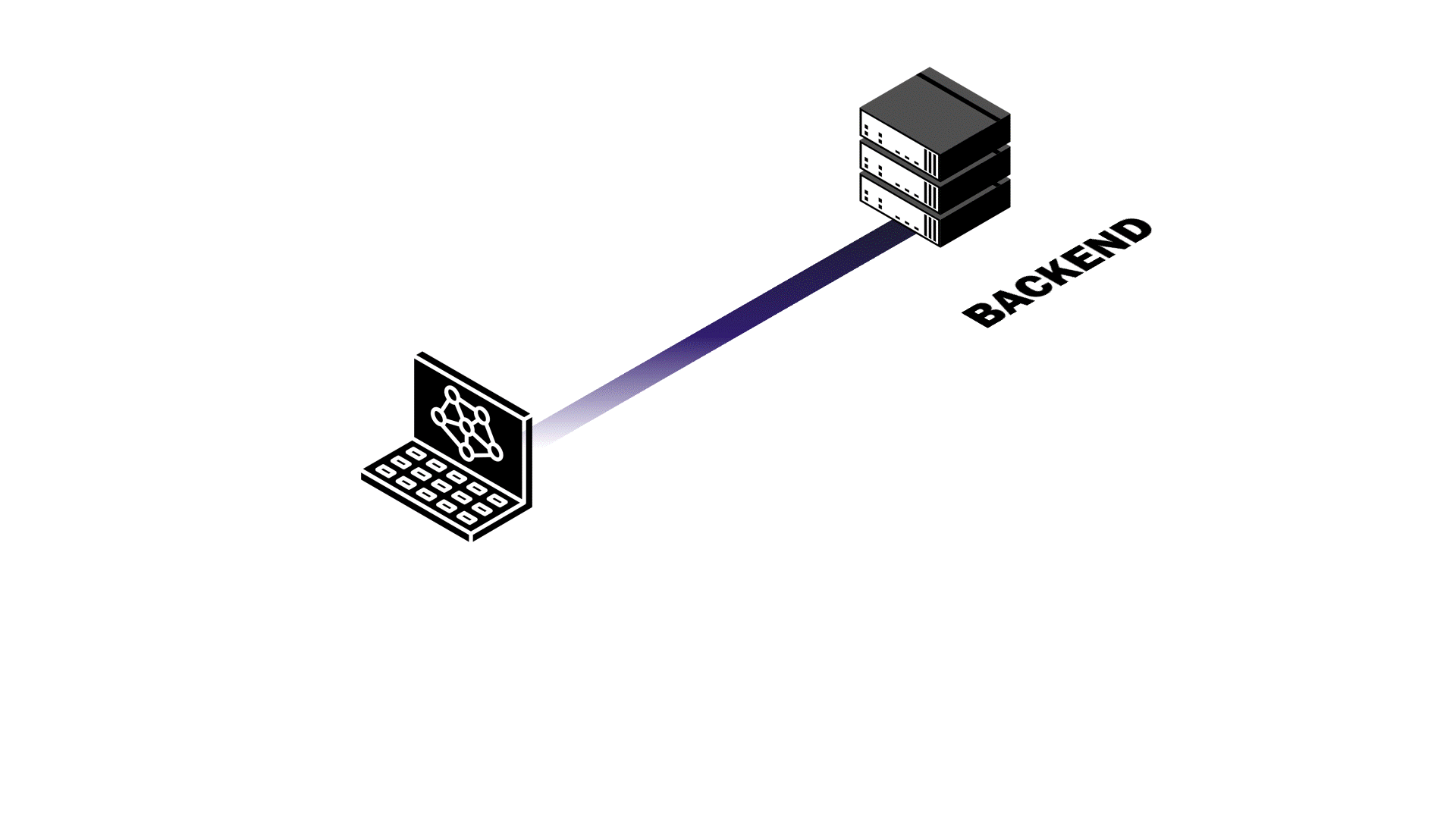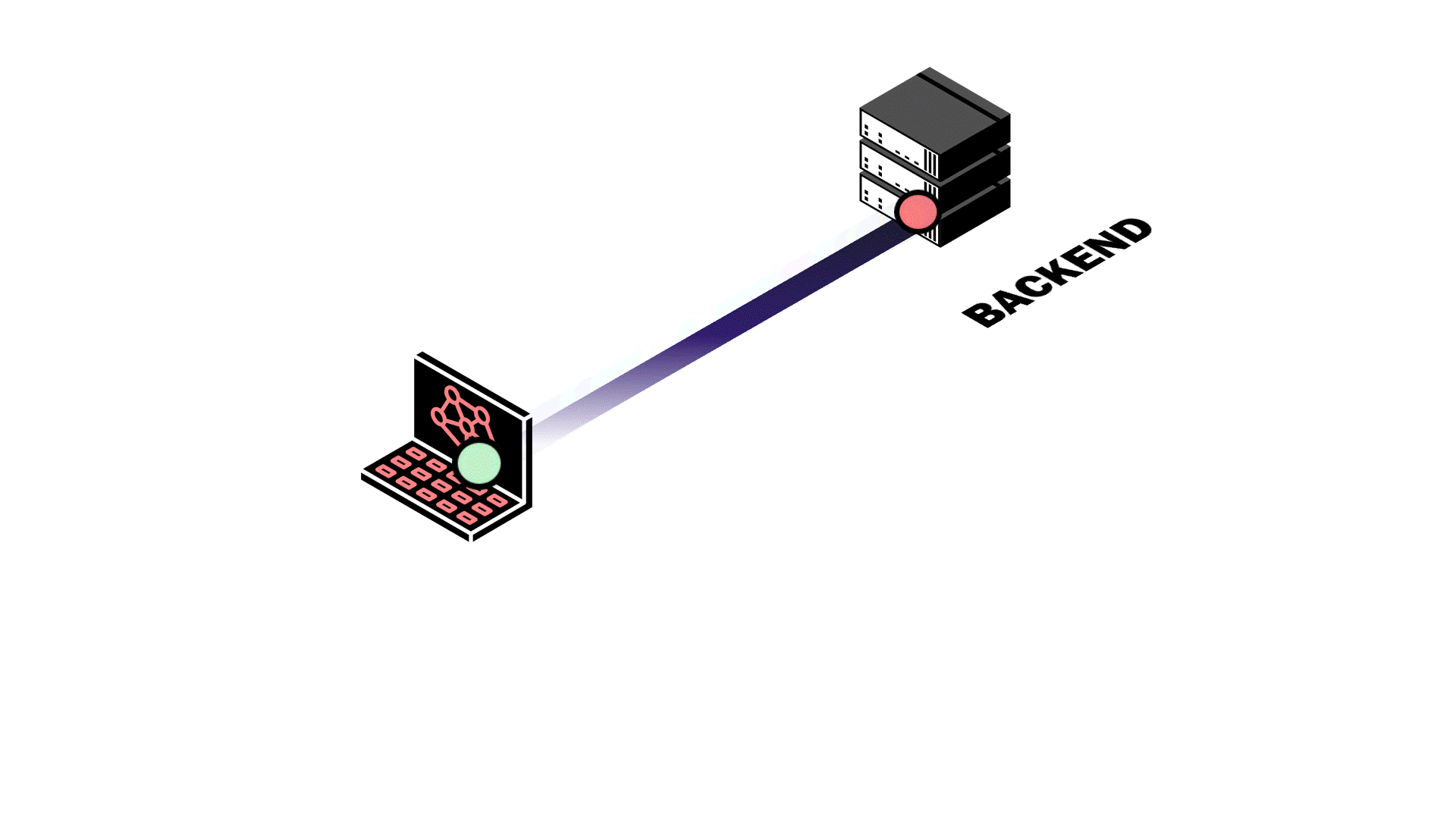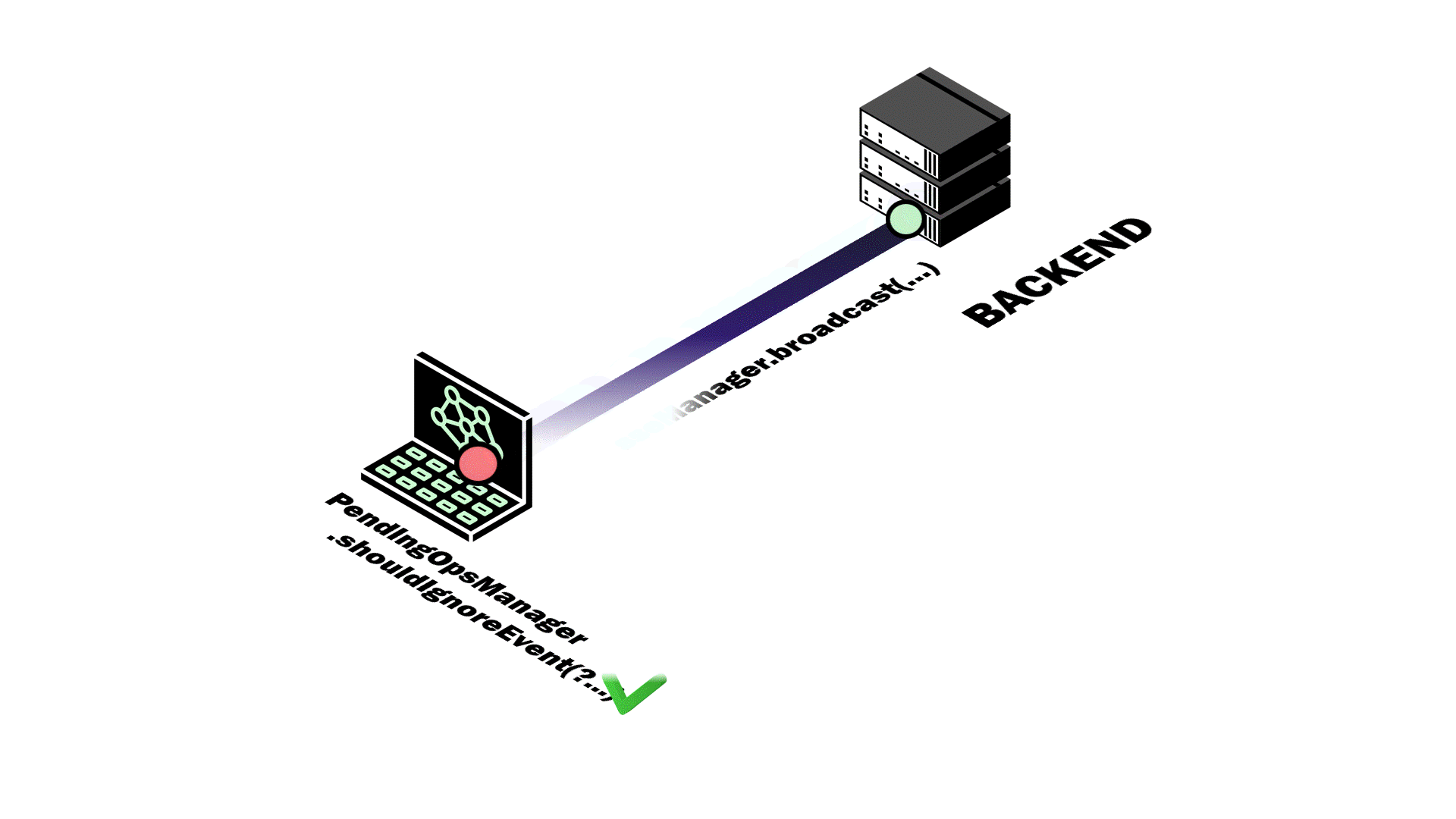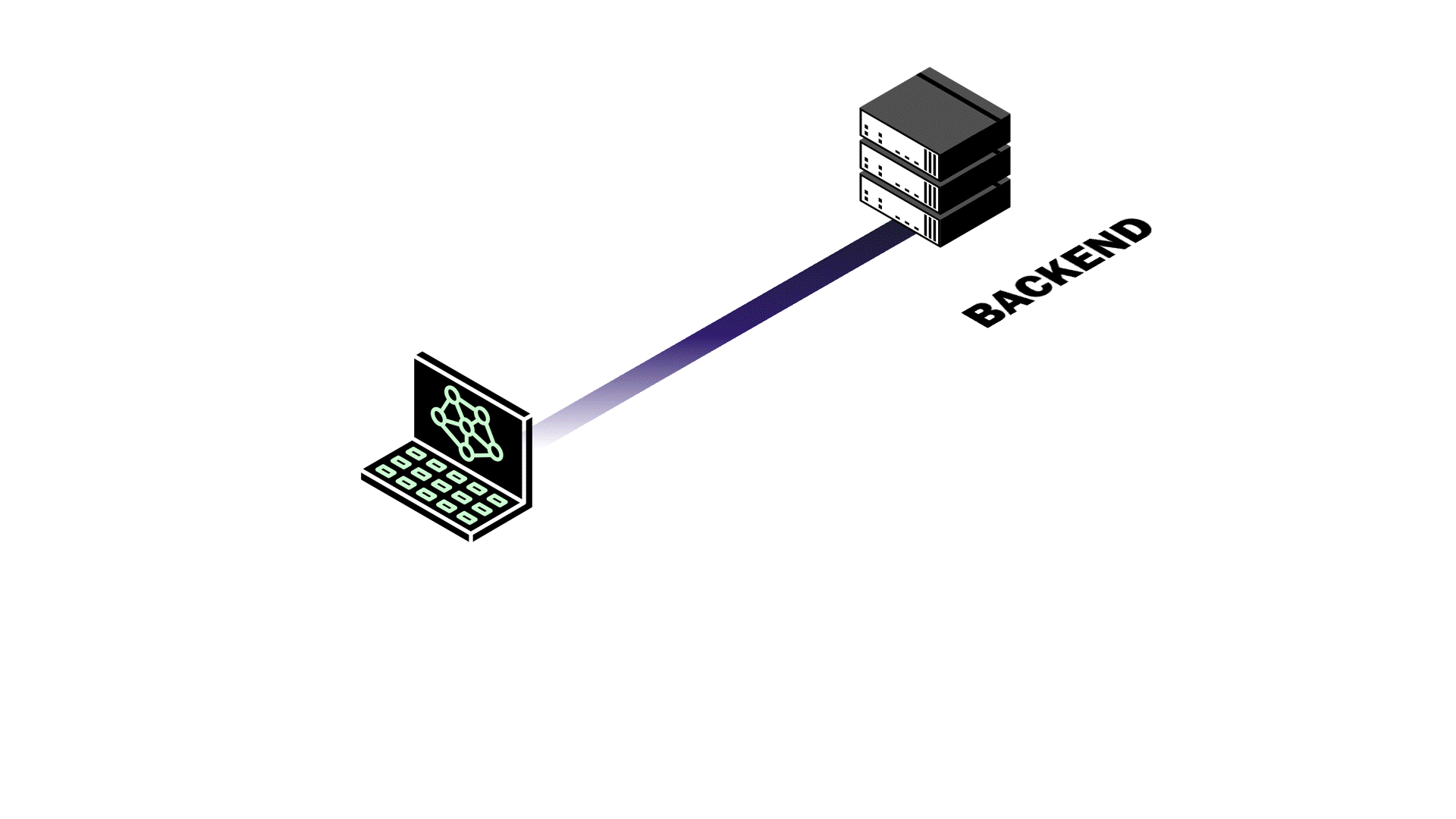
client performs a mutating database operation, the Pendulum SDK generates
and stores a unique operationId. If the events service pushes
data with a matching operationId, the SDK ignores it since the
change originated from that client and the frontend state was already
updated optimistically. While this requires additional infrastructure and
cleanup mechanisms, developers get the best of both worlds without any
additional code. Applications get the immediate responsiveness of optimistic
updates and the consistency ensured by server-first updates.
Authentication and Authorization
We mentioned authentication management as a key feature expected by anyone
using a BaaS platform. Frontend developers expect BaaS platforms to handle
authentication and abstract the complexity away into easy-to-implement
methods. To achieve this, we provide authentication methods defined directly
on the SDK's auth class as seen in the table below. We followed
industry best practices when handling sensitive password information by only
storing and comparing password hashes during registration and authentication.
| Method | Description |
|---|---|
register(username, email, password) | Creates a new user account with the given credentials. Returns a
JSON object with success boolean and user details including
username, email, and role (defaults
to 'user'). If registration fails, returns success: false with an error message. |
login(identifier, password) | Authenticates a user with username/email and password. Returns a
JSON object with success boolean, userId,
and a JWT token with 24-hour expiration. If login fails due to
invalid credentials, returns success: false with an error
message. |
logout() | Invalidates the current user session and clears the stored
authentication token. Returns a JSON object with success boolean and confirmation message. The client automatically removes
the token from storage, requiring users to log in again for protected
operations. |
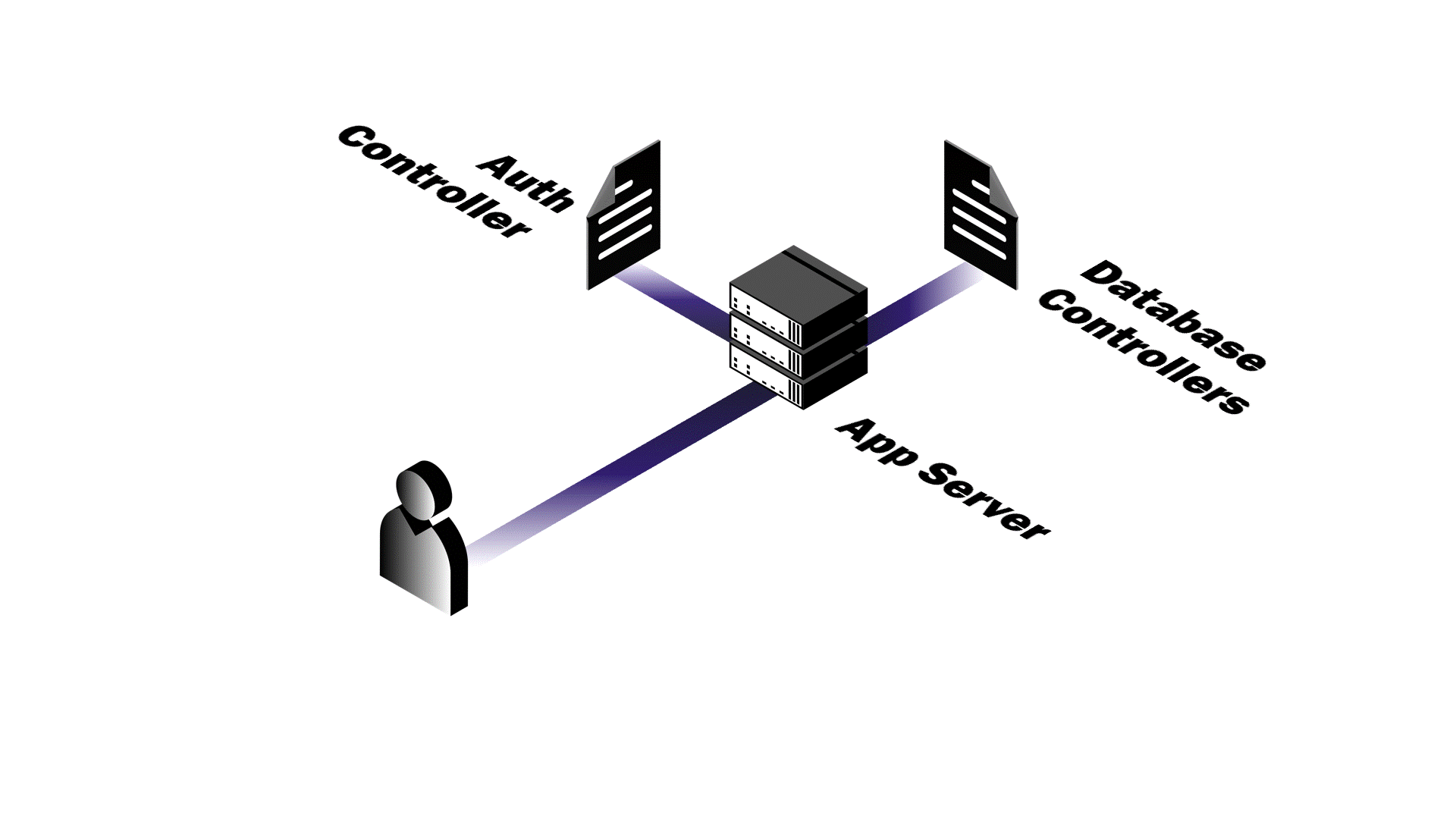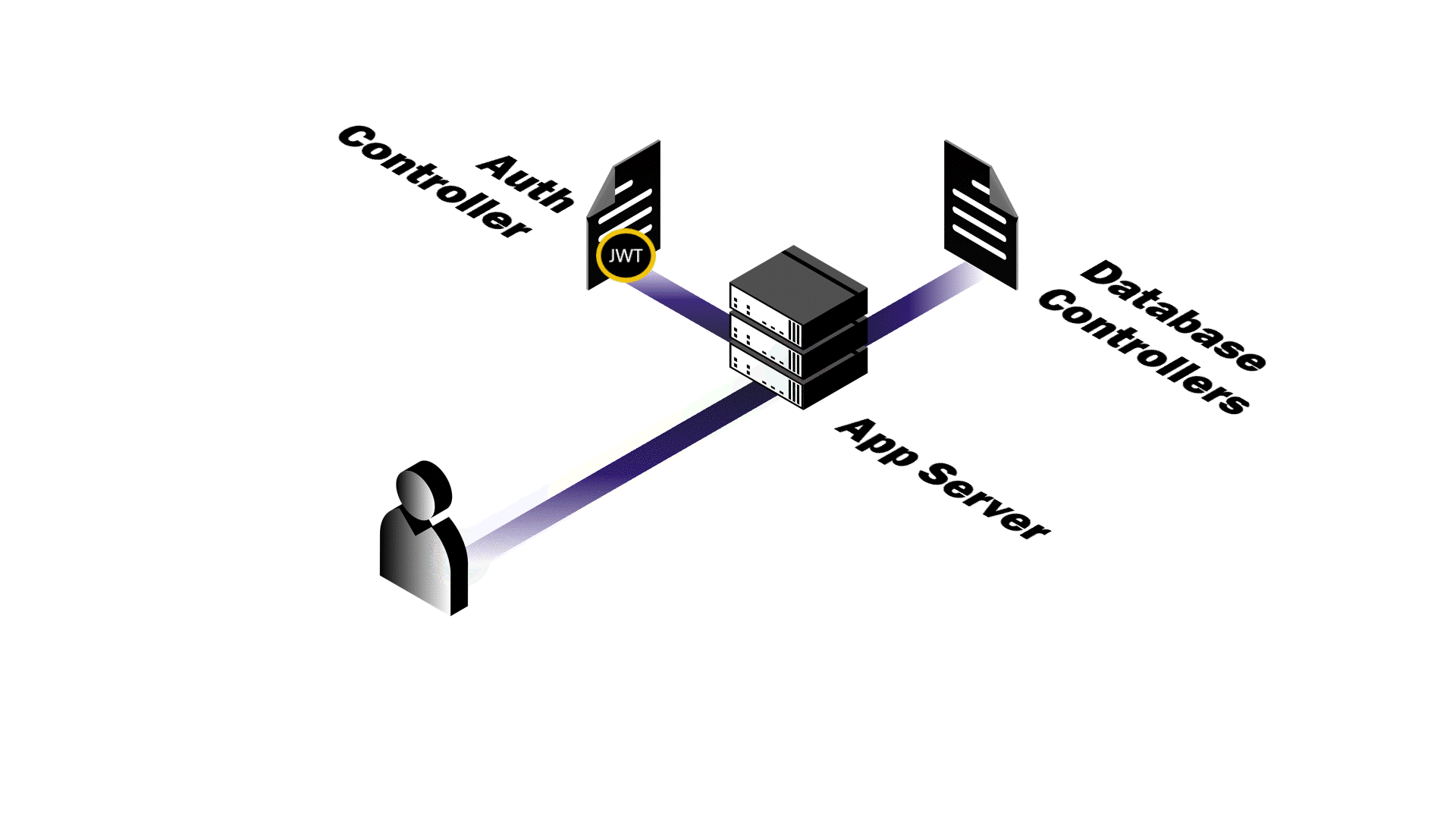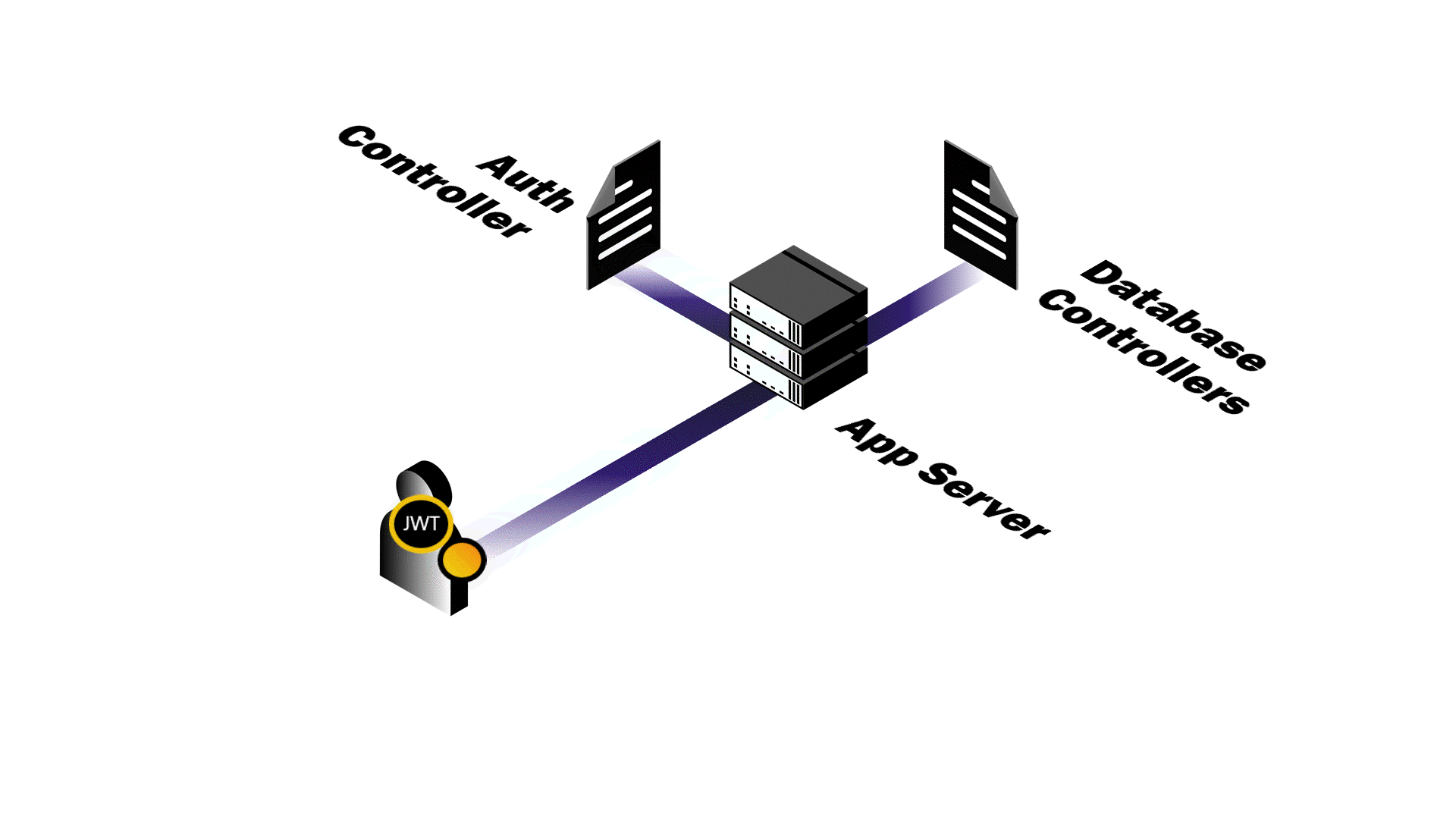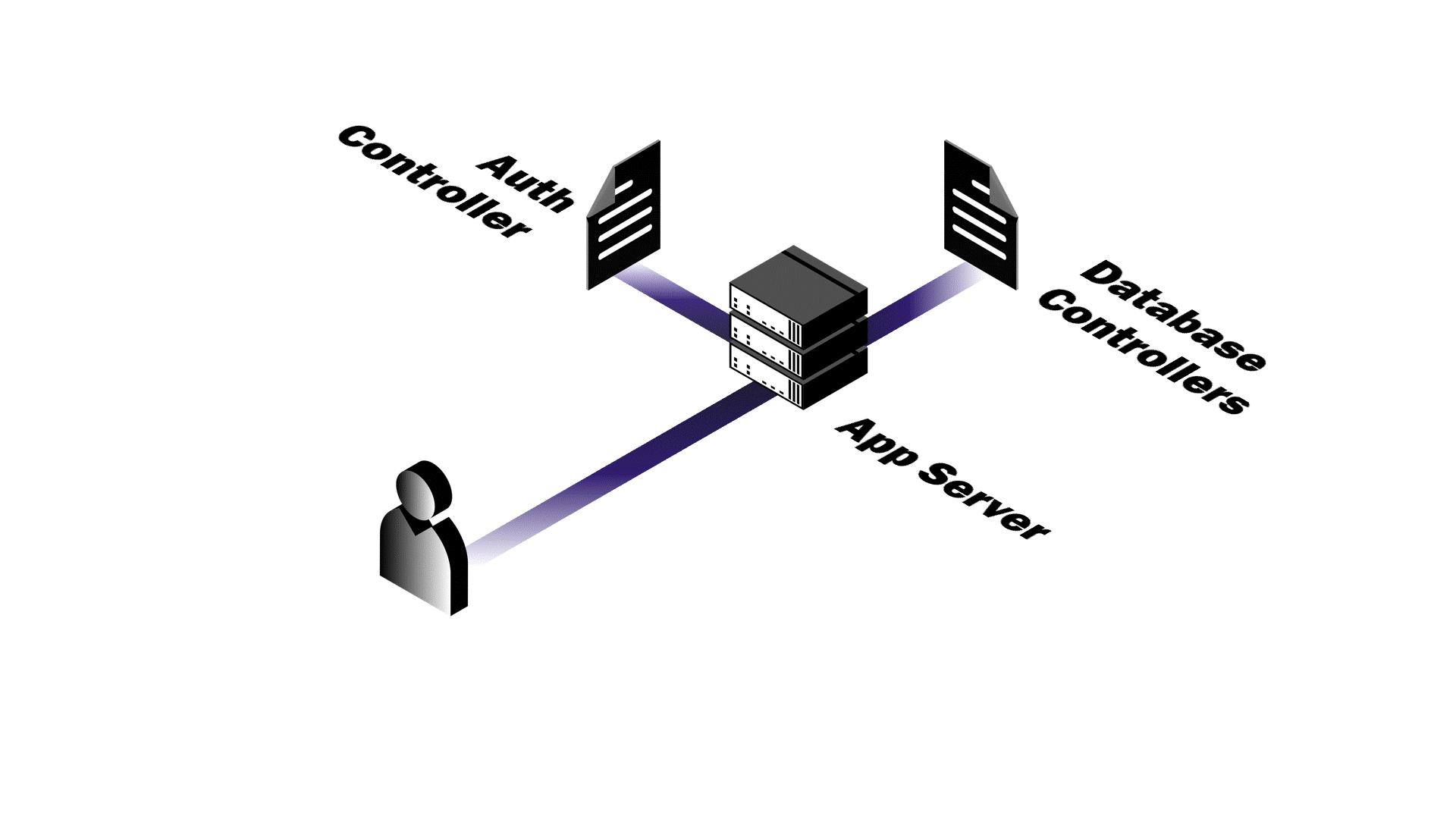
Authentication in Practice
After a successful login, Pendulum generates a JSON Web Token (JWT) whose
payload contains information pertaining to the user like their userId and
role. The token is signed using a private key, given a 24-hour
expiration, and sent back to the client in the response. We transmit the JWT
in the response’s Authorization header. The Authorization header approach provides greater control over when tokens are sent and maintains
cleaner separation of concerns between authentication and other HTTP functionality.
It's also the standard method for authenticating API requests in modern web development.
While this method typically adds more burden on the developer to manage data
on the client side, Pendulum’s SDK handles client-side tokens for developers
out-of-the-box.
We considered using cookies due to several advantages like automatic
inclusion in requests and better protection against Cross-Site Scripting
attacks with HttpOnly and Secure flags. However, cookies
can be vulnerable to Cross-Site Forgery Request (CSRF) attacks and their automatic
transmission can be inefficient for non-API requests.
Authorization
Now developers have a way to implement authentication into their application, but we had to determine how users could restrict access to resources based on the roles assigned to users — a practice referred to as Role-Based Access Control (RBAC). MongoDB’s lack of row-level security features required us to implement RBAC at the application level.
With Pendulum we used a simple, three-role system:
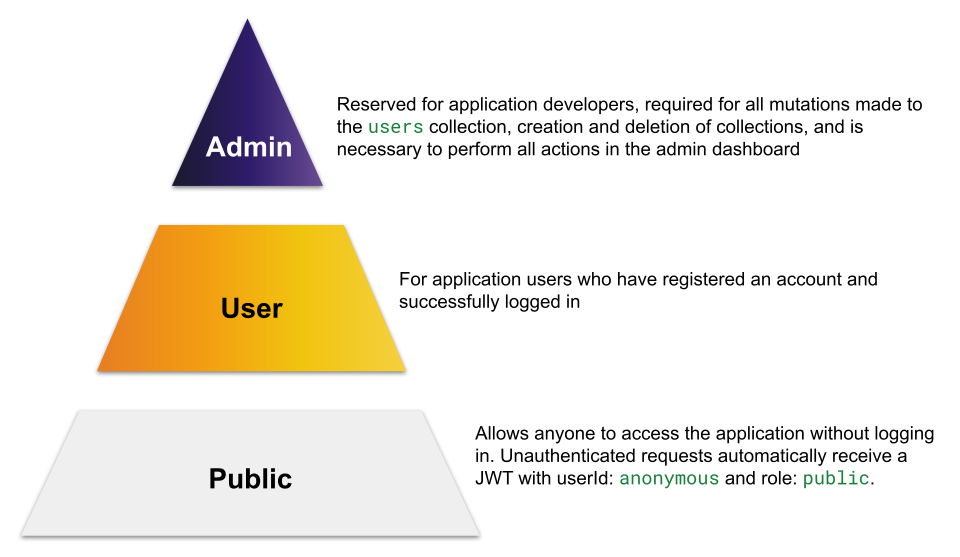
We created a collection_metadata collection in MongoDB to keep track
of all existing collections and their permissions. This is combined with an in-memory
CollectionsManager class to serve as the interface for querying
and mutating collection-level permissions. Every collection has permission rules
for each CRUD operation, where a rule represents the lowest-level role allowed
to perform that action. For example, a collection with the update
operation set to user means that only requests with user or admin roles in their token payloads are permitted — the public role cannot perform this action. These rules are then enforced for all requests
to the application service through centralized middleware functions that validate
tokens and enforce RBAC rules.
We chose to assign the public role for all CRUD operations as the
default for all new collections. With flexibility in mind, we leave it to the
developer to determine and set the appropriate permission levels for collections
— the Pendulum admin dashboard makes this straightforward and updates are reflected
and enforced in the application in real time.
Admin Dashboard Design
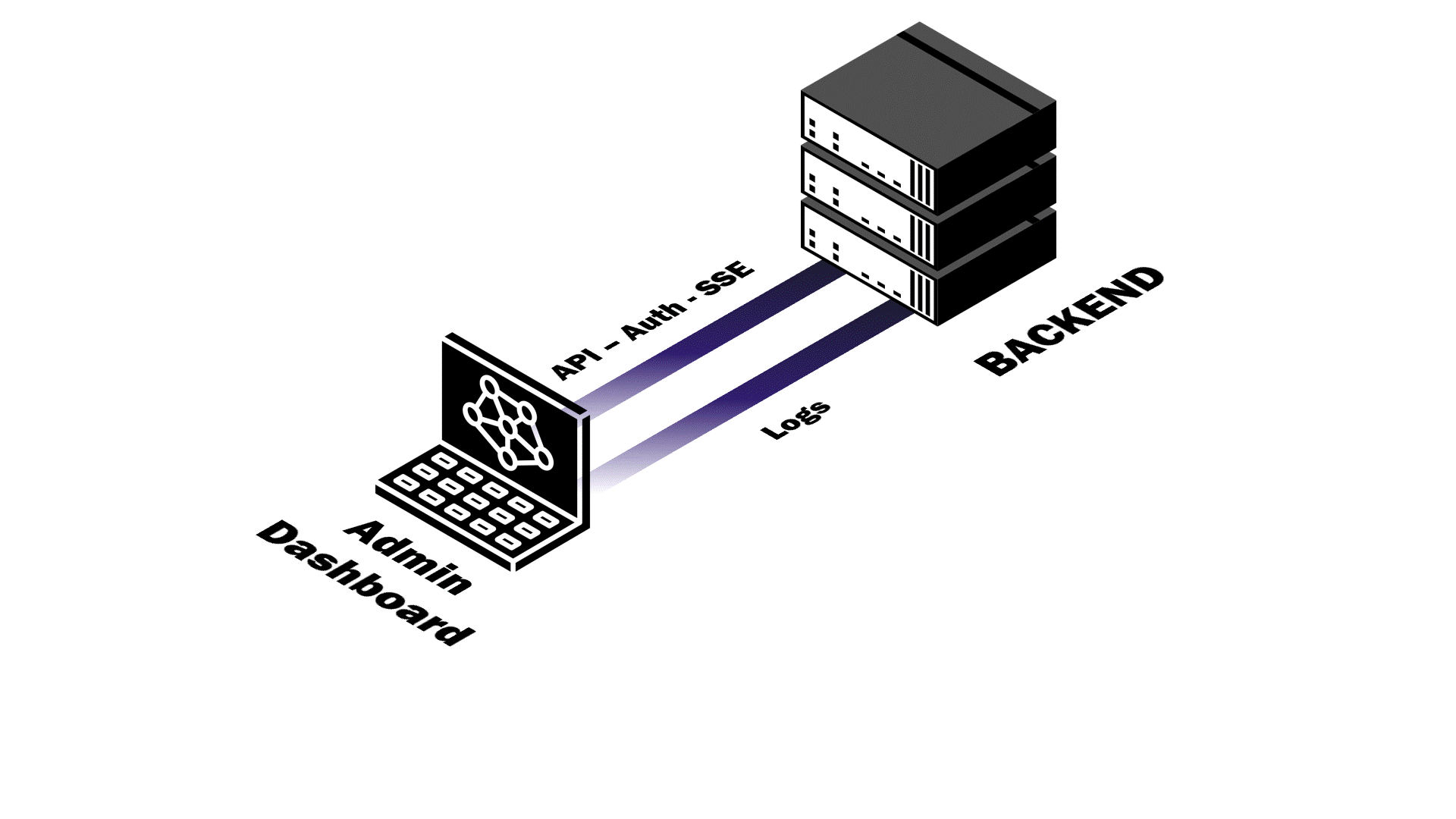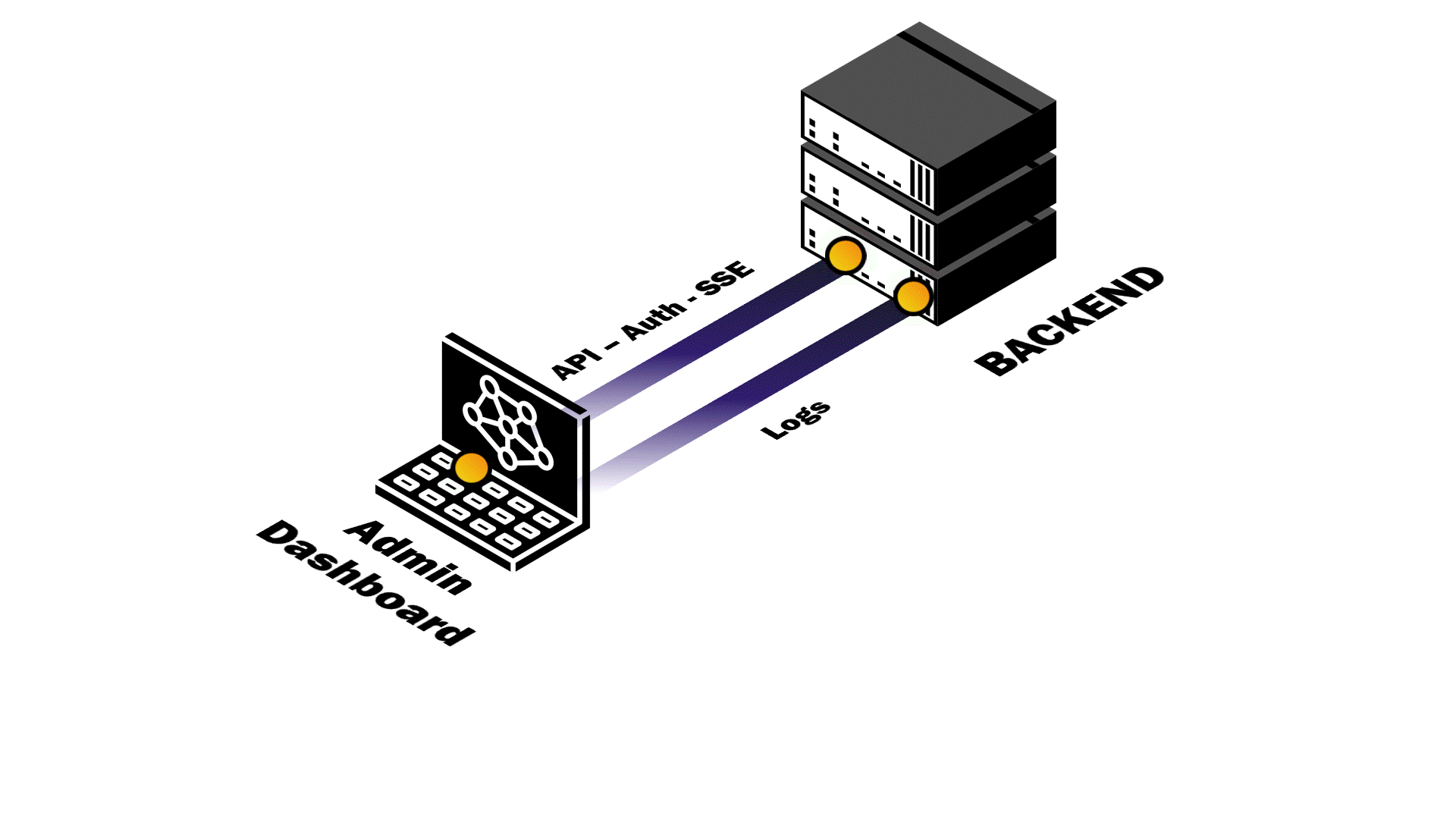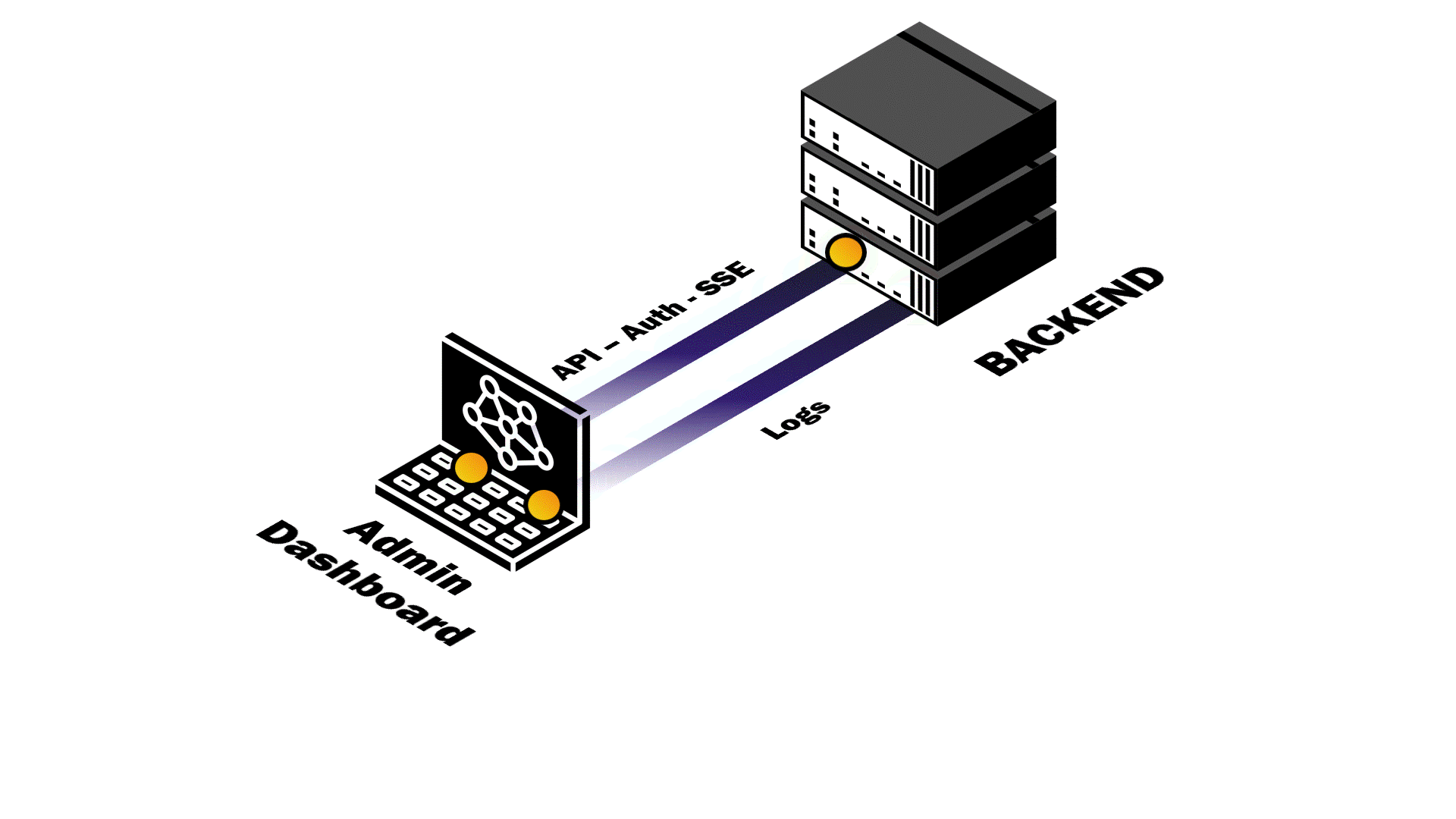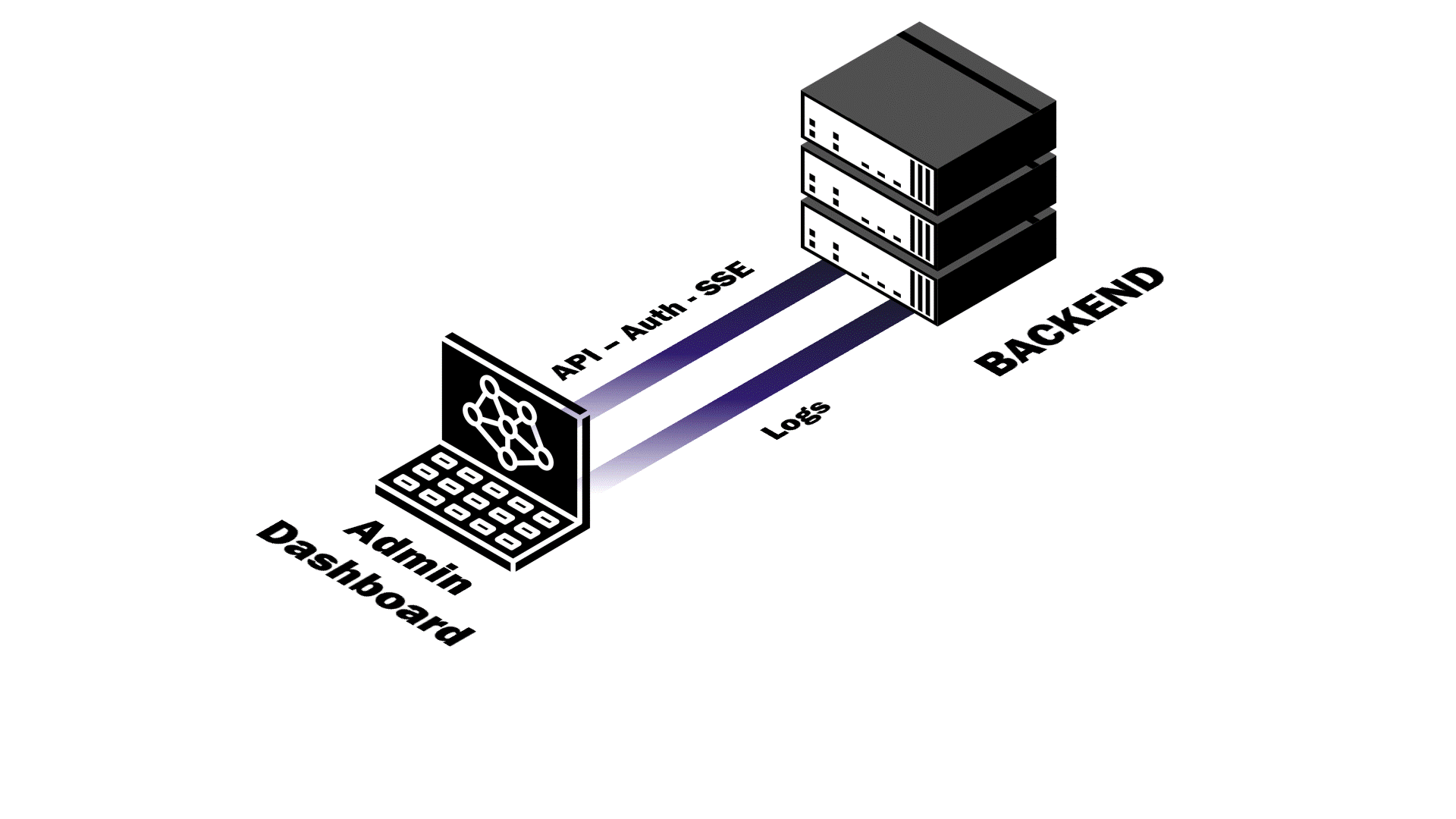
Pendulum’s Admin Dashboard exists to give developers a centralized interface for managing backend data. We needed to display system-level information like logs while also keeping the UI synchronized with real-time data changes. In other words, how could we accurately reflect the most up-to-date backend state to the application’s developers? The solution was right in front of us — use our own platform.
The SDK’s database methods made implementing data manipulation functionality straightforward, and the automatic connection to our real-time events service provided seamless real-time updates for data displays. All it needed was a dedicated SSE connection in our application service to stream logs in real-time. Building off our existing middleware infrastructure, we implemented the logging SSE stream with a middleware in all CRUD API endpoints. Request details like request method, URL, response status, client IP, and authenticated user ID are captured, formatted into structured log entries, and immediately broadcast to all connected admin clients. Developers now get real-time API monitoring without needing to poll log files or refresh the dashboard.
With this dual-stream architecture, developers can debug collection-level issues by correlating database events with API calls and monitor system health through response status patterns. By choosing to serve our admin dashboard’s static assets directly from the app service, we achieved reduced network latency for even faster data synchronization and avoided needlessly over-complicating our backend architecture.
Bridging AI Agents and Backend Management
We recognized that developers already use AI assistants for coding help but can't effectively use them to get insights about their deployed backend systems. The Model Context Protocol was perfect for extending AI workflows to backend management — providing a standardized way for AI agents to interact with deployed resources without building custom integrations for each AI platform.
The Pendulum MCP server connects to deployments via HTTP and translates natural language queries into specific backend operations. We implemented five core tools:
| Tool | Usage |
|---|---|
check-health-status | Get real-time insights into the health and status of both backend services. |
get-active-users | Returns the number of users currently connected to your application. |
infer-schema | Given a collection, infers and generates JSON that represents the schema of the collection. |
validate-schema |
Given a collection and an expected schema, identifies any documents
in the collection that do not conform to the expected schema.
Returns _id values for those that do not match.
|
start-realtime-logs |
Monitor and log all realtime events as they are broadcast out to
active users for a specified amount of time. Log file is
timestamped and written to user's local /tmp
directory.
|
Each tool generates admin JWT tokens for backend authentication and formats responses as structured JSON that AI agents can interpret and present conversationally. The server uses the stdio transport protocol to communicate with AI clients. This allows seamless integration with existing AI workflows without requiring additional network configuration or authentication beyond the initial setup credentials.